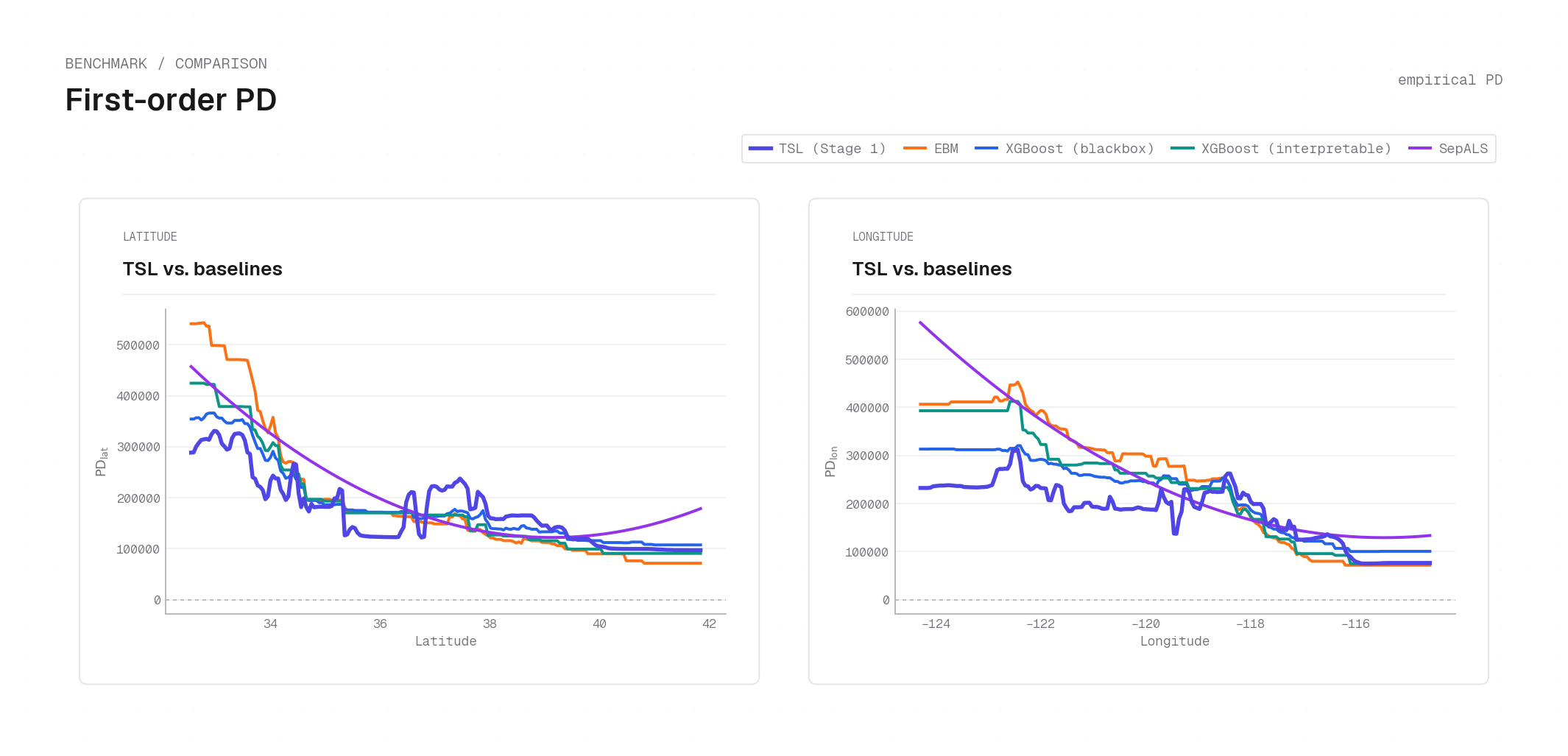
Partial dependence¶
Partial dependence (PD) is the central interpretability tool for TSL. The key result is that for a separable model a 1D PD curve recovers the exact factor shape — not a contaminated main effect — so TSL's PD plots are model-native explanations rather than post-hoc approximations.
The problem with additive PD¶
The partial dependence of feature \(j\) is the marginal expectation
For an additive model with functional-ANOVA decomposition \(m(\mathbf{x}) = \sum_{S\subseteq[p]} m_S(\mathbf{x}_S)\) under the usual marginal identification constraint, the PD of \(x_1\) collapses to the intercept plus the main effect, \(\mathrm{PD}_1(x_1) = m_\emptyset + m_1(x_1)\), and therefore carries no information about any interaction term \(m_S\) with \(1\in S\) and \(|S|\ge2\). Strong interactions can leave no signature on the 1D PD at all (see the masked-interaction example).
Faithfulness for separable models¶
For a single separable product \(h(\mathbf{x}) = \prod_{j=1}^p h_j(x_j)\), marginalizing over the other coordinates leaves the factor shape intact up to a constant:
The interaction structure lives in the product form itself, so PD recovers \(h_j\) exactly rather than collapsing it to a main effect.
Proposition 1 — partial dependence decomposition¶
For a TSL estimator, fix a stage \(\ell\) and coordinate \(j\) and define
Then the 1D partial dependence of each signed branch factorizes into the factor shape times a constant:
Moreover, with \(\bar{m}_{\pm}^{(\ell)} \coloneqq \mathbb{E}[\hat{m}_{\pm}^{(\ell)}(X)]\) and \(Z_{\pm}^{(\ell)} \coloneqq \mathbb{E}\bigl[\prod_{j=1}^p \mathrm{PD}_{\pm,j}^{(\ell)}(X_j)\bigr]\), the stage admits an exact reconstruction from its 1D curves:
So each stage — and any explanation built from its factors — is recoverable from 1D PD summaries up to a single scalar normalizer per stage and sign branch. TSL's 1D PD plots therefore recover the fitted factor shapes (up to the constants \(C^{(\ell)}_{\pm,j}\)) without a surrogate.
Implementation note — empirical marginalization
TSL.compute_partial_dependence_function (tsl-py/src/lib.rs) marginalizes over the
empirical joint distribution of the other features, not a product-of-marginals
reference, so the constants \(c^{(\ell)}_{\pm,j}\) are estimated correctly under feature
correlation. The function returns, per stage, the \((C_+, C_-)\) constants and the curve
values. The algebraic factorization holds for any reference distribution; only the
statistical meaning of the average depends on that choice.
Backbone–tilt reconstruction from PD¶
The backbone and tilt can be read directly off the signed-branch PD curves (in the normalized gauge):
The backbone is a magnitude summary that cannot cancel even when the signed stage PD \(\mathrm{PD}_j^{(\ell)} = \mathrm{PD}_{+,j}^{(\ell)} - \mathrm{PD}_{-,j}^{(\ell)}\) is near zero; the tilt captures the signed direction. Only the \((+)\) and \((-)\) PD curves per feature need be plotted to faithfully explain the model.
Signed-branch PD and the masked interaction¶
Consider independent features with \(Y = x_1^2\,x_2\,(1+x_3) + \varepsilon\) and \(\mathbb{E}[1+X_3]=0\). Then the population 1D PD of \(x_1\) is identically zero — \(\mathrm{PD}_1(x_1) = x_1^2\,\mathbb{E}[X_2]\,\mathbb{E}[1+X_3] = 0\) — even though \(x_1\) has a strong effect. Every model (TSL included) yields a near-zero 1D PD here, consistent with the population identity.
TSL's signed-branch PD escapes this trap: the backbone \(b_j^{(\ell)}(x_j)\) recovers the
quadratic effect of \(x_1\) while the tilt stays small, so the magnitude is exposed even
though the signed PD cancels. This is the practical payoff of the two-tensor form. The
synthetic.py example reproduces the figure; see Examples.
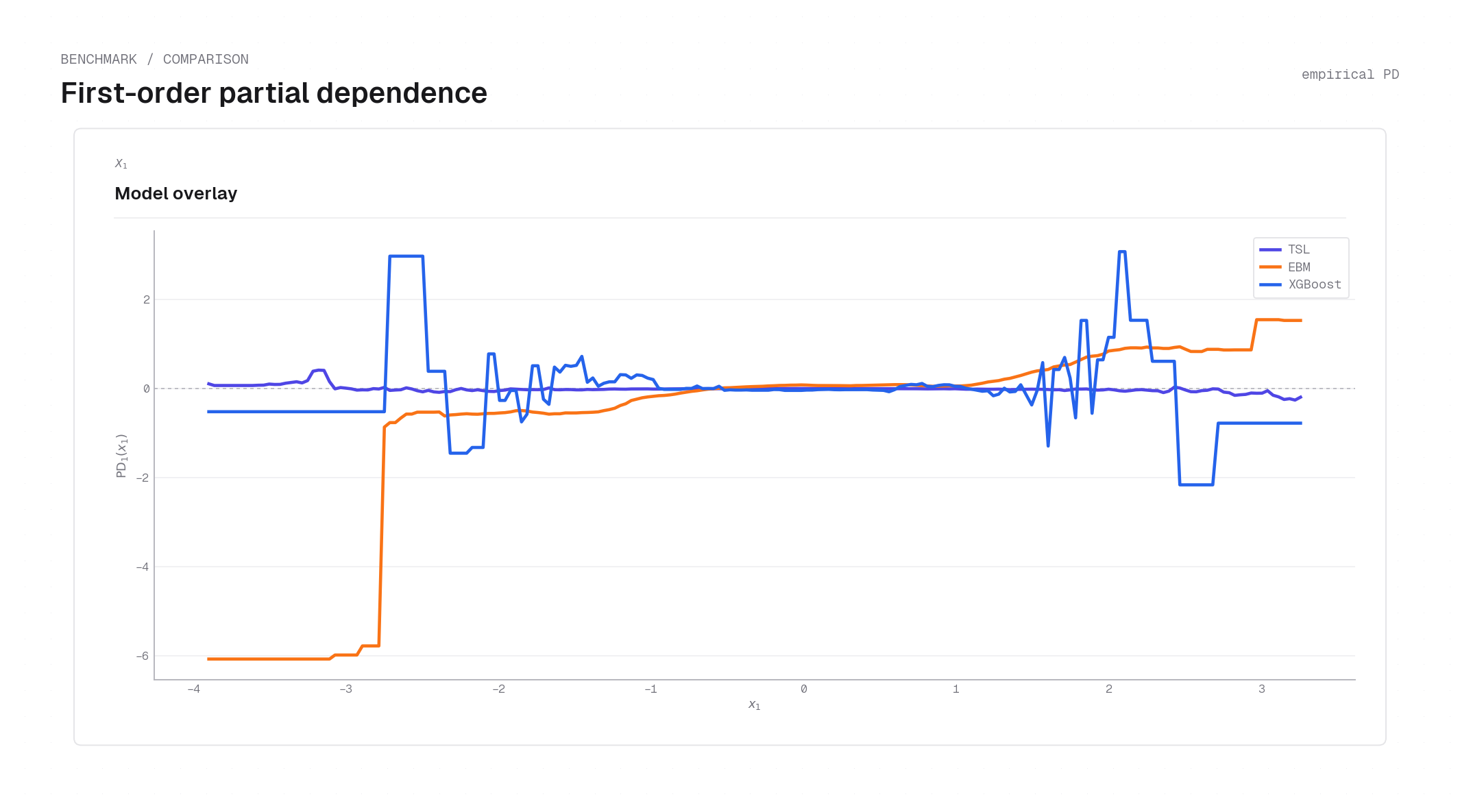
synthetic.py example script.Derived diagnostics¶
The Python layer builds several interpretation primitives on top of the PD math:
- ICE curves —
compute_ice_curvestraces individual conditional expectations (per-observation analogues of PD), scaled byscaling_plus/scaling_minus. - First-order PD per feature —
compute_first_order_partial_dependence_functions. - Feature importance — variance-based backbone and tilt importance per stage, rolled up across stages by an energy weight into a combined score \(I_j\) (defined below).
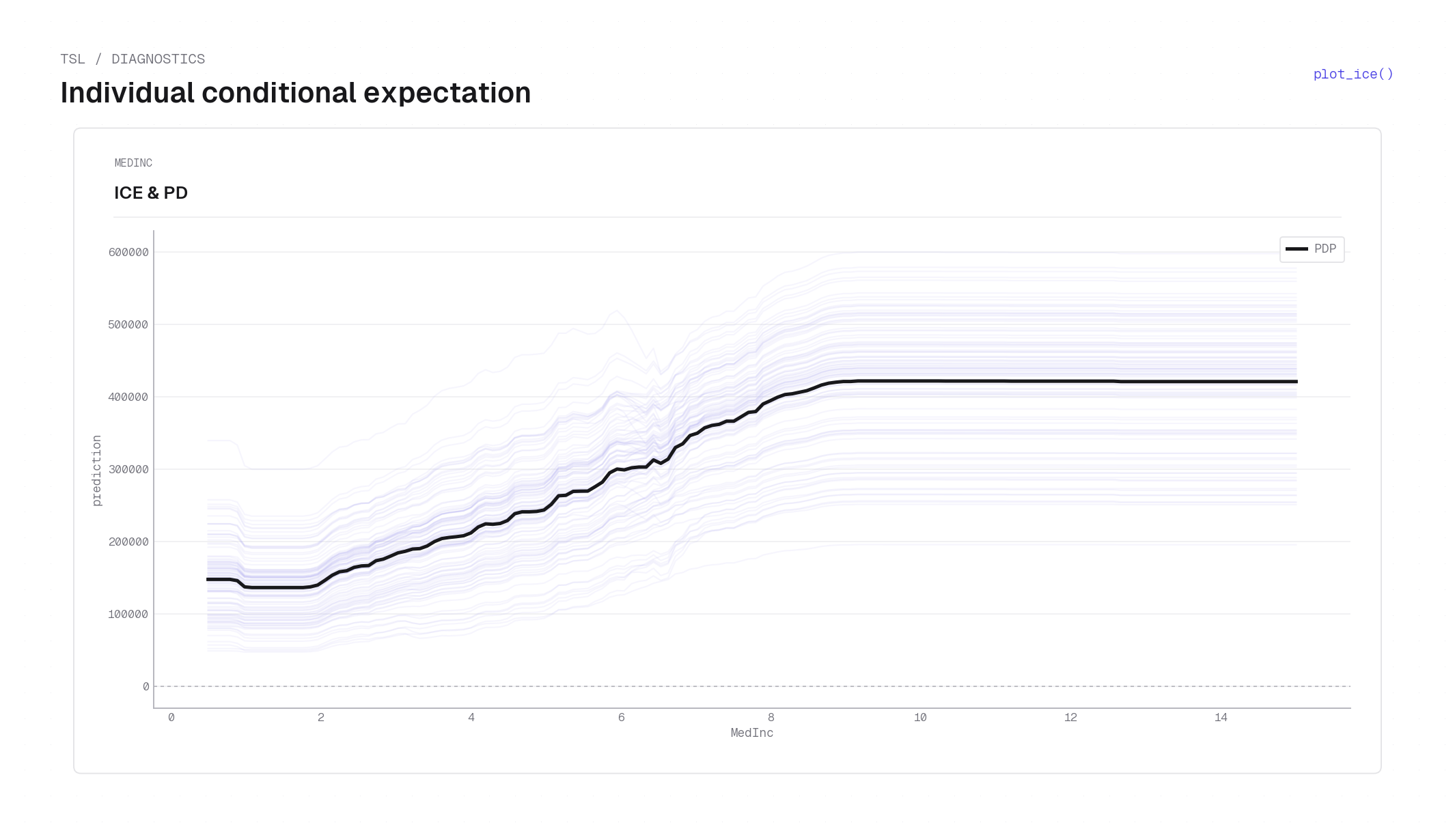
plot_ice for the API.Feature importance¶
Feature importance reads off the backbone–tilt decomposition: a feature matters to a stage to the extent that its backbone (the magnitude gate) or its tilt (the signed direction) varies across the data. Evaluate the per-feature factors on the training sample \(\{x^{(i)}\}_{i=1}^n\) and take their empirical variances. For stage \(\ell\) and feature \(j\),
writing \(\mathrm{Var}_n[g] = \tfrac1n\sum_{i}\bigl(g(x_j^{(i)}) - \tfrac1n\sum_{i'} g(x_j^{(i')})\bigr)^2\) for the empirical variance over the sample. The backbone variance is taken on the log scale because the backbone enters the stage multiplicatively; under the normalization gauge \(\mathbb{E}[\log b_j^{(\ell)}] = \mathbb{E}[d_j^{(\ell)}] = 0\), so both are second moments about zero. A feature whose backbone and tilt are flat across the sample contributes nothing to that stage and scores zero.
Stages are then weighted by how much they actually move the prediction — their energy, the mean-squared stage contribution:
where \(\hat{m}^{(\ell)} = \hat{m}_+^{(\ell)} - \hat{m}_-^{(\ell)}\) is the stage's signed
contribution to \(\hat{m}\) (the per-stage OLS scalings scaling_plus/scaling_minus are
folded in; see StagePredictor). The per-stage importances
aggregate to global scores, and a single combined score folds the two channels together
with a tilt weight \(\gamma \ge 0\) (default \(1\)):
compute_per_stage_feature_importance returns the per-stage grids
\(I_j^{b,(\ell)}, I_j^{d,(\ell)}\), compute_aggregated_feature_importance returns the global
\(I_j^b, I_j^d\) together with the weights \(\omega_\ell\), and
compute_combined_feature_importance returns \(I_j\) — all rendered by
plot_feature_importance.
All of these are plotted by the tensorsl.plot helpers — see the
Plotting reference.